AI大模型参加高考全科目评测,文科总分过一本线,理科过二本线
高考信息 2024-07-23 571
人工智能大模型参加中国高考,可以得几分?近日,大模型开源开放评测体系“司南”(OpenCompass)对中外7个人工智能大模型进行了今年高考(新课标卷)全科目测试,结果显示:上海人工智能实验室“书生·浦语2.0系列文曲星”大模型、阿里“通义千问”大模型Qwen2-72B、OpenAI的GPT-4o排名文、理科前三名,前三名“考生”的文、理科成绩分别超过了一本、二本线(以今年高考人数最多的河南省分数线为参考)。
阅卷老师认为,尽管头部大模型在高考中发挥较好,但与优秀真人考生仍存在明显差距,在逻辑推理、知识灵活运用方面能力较弱,有待研发团队今后加强这些方面的训练和调优。
国产大模型考分超过GPT-4o
司南相关负责人介绍,组织大模型参加高考,是为了评测当前大模型的真实水平,找准问题,推动技术进步。此次高考评测采用全卷考试形式,进行全卷评分,大模型“考生”要完成除英语听力外(默认大模型获得满分30分),包括带图题在内的所有题型。
参与评测的6个大模型均为开源模型,分别是阿里巴巴开源的Qwen2-57B和Qwen2-72B、上海人工智能实验室开源的“浦语文曲星”、智谱华章开源的GLM-4-9B、零一万物开源的Yi-1.5-34B、法国企业Mistral开源的Mixtral8x22B。这些模型都在今年高考前开源,排除了泄题的可能性。
此次评测还引入了一个闭源大模型GPT-4o,因为它是国际领先的大模型,用于比对参考。为确保评分和真实高考基本一致,“司南”团队邀请有高考阅卷经验的老师打分。
评测结果显示,阿里“通义千问”大模型Qwen2-72B以546分成为“文科状元”,“浦语文曲星”以468.5分成为“理科状元”,这两个国产大模型的考分都超过了“非开源国际插班生”GPT-4o(文科531分,理科467分)。
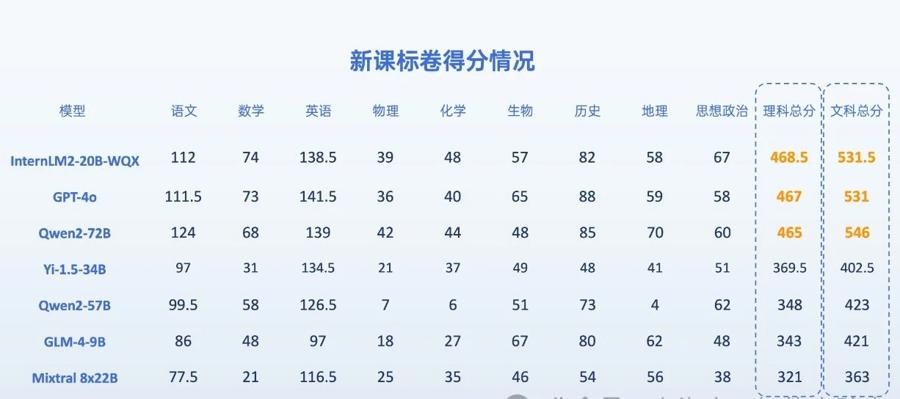
7个大模型参加今年高考(新课标卷)的得分情况
以河南省录取批次线为参考,Qwen2-72B、“浦语文曲星”、GPT-4o的文科成绩均超过一本线,展现出大模型在语文、历史、地理、思想政治等科目上深厚的知识储备和理解能力。而在理科考试上,它们的整体表现弱于文科,反映出大模型在数理推理能力上存在短板。当然,前三名的理科成绩均超过二本分数线,体现了大模型在数理推理方面的提升潜力。
自创唐诗“骗”过阅卷老师
完成阅卷后,老师们认为,除了数理推理能力较弱,大模型还存在反思能力、空间想象能力、物理和化学实验理解能力等短板。
例如,数学考卷中一题为:
已知A(0,3)和P(3,3/2)为椭圆C:x²/a²+y²/b²=1(a>b>0)上两点
(1)求C的离心率
(2)若过P的直线l交C于另一点B,且△ABP的面积为9,求l的方程
由于在解题过程中出现计算错误,出现了不正确的求解K值方程式:
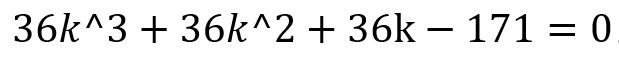
不正确的求解K值方程式
面对如此难解的方程式,大模型依然选择“硬解”,直接蒙了一个答案。而大多数人类考生如果发现计算存在问题,会反思此前若干步骤的计算是否有误、进行检查,而非“硬解”方程式。
在空间想象能力上,大模型解答一道立体几何大题的平均得分率仅为8.5%,远低于数学平均得分率35.5%。通过检查大模型的答题,评测团队发现,它们往往会作出一些完全不符合空间逻辑的推断,例如:

完全不符合空间逻辑的推断
大模型对实验设备和基本实验步骤的理解也很有限。在回答化学题“取100mmol己-2,5-二酮应选取何种仪器”时,除了GPT-4o,其他大模型都认为应使用量筒,没有考虑需求数量对仪器选取的影响。其实,如此少量的试剂应选用酸式滴定管。在回答物理题“多用电表测量电压表内阻”时,所有大模型均无法准确读出图中的电阻值,表明它们对实验设备的理解很有限。
一本正经地虚构内容,是大模型解答文科题目时会出现的问题。例如,语文考卷中一道填空题为:“唐代诗人写时事,常常托之于汉代,如‘____,____’,就是借汉喻唐,以古方今。”一个大模型的回答是“想知汉武宫香径,请看长安市醉人”。这句诗存在对仗且的确是“以古方今”,一些阅卷老师误以为唐代诗人写过这句,认为大模型答对了,但实际上它是人工智能虚构的,属于“原创”诗句。
专家指出,大模型的“幻觉”是一个亟待解决的问题,要通过“通专融合”等途径有效解决,这样才能让大模型应用于各个专业领域。
本文转载自:https://export.shobserver.com/baijiahao/html/774592.html
文章来源于网络,如有版权问题请联系我们删除!
推荐阅读 AI大模型“高考”成绩公布:几乎都偏文,数学有点差,解题思路特别“轴” AI参加高考,为何偏科严重 重磅!四川发布高考招生新规→ 2024年四川高考时间是什么时候? 陕西高考有新动向!考生选科首先得明确专业方向 新高考选科:一道决定人生轨迹的“多选题”
点击访问更多新期教育网的 高考信息资讯
上一条: 宿州市首封高考录取通知书送达 下一条: 浙江高考一段投档线公布,不少去年高分专业今年未招满
![]()
暂无数据